Note
Go to the end to download the full example code.
Mean vs Median
This script compares the errors based on mean and median. It shows that the errors based on mean are more sensitive to outliers than the errors based upon median.
import os
import sys
import numpy as np
import easy_mpl
from easy_mpl import plot
import SeqMetrics
from SeqMetrics import mse, med_seq_error, mae, median_abs_error, mape, mdape, me, mde
print('python version: ', sys.version)
print('OS Name: ', os.name)
print('numpy: ', np.__version__)
print('easy_mpl: ', easy_mpl.__version__)
print('SeqMetrics: ', SeqMetrics.__version__)
python version: 3.8.20 (default, Nov 25 2025, 20:14:35)
[GCC 9.4.0]
OS Name: posix
numpy: 1.24.4
easy_mpl: 0.21.5
SeqMetrics: 2.0.1
Consider that we have two outputs from our model. One output is normal and the other has an outlier. We will compare the errors based on mean and median.
true = np.random.random(100)
pred = np.random.random(100)
pred_o = pred.copy()
pred_o[2] = 40
First see that how the array pred_o has just one outlier.
The outlier is at index 2.
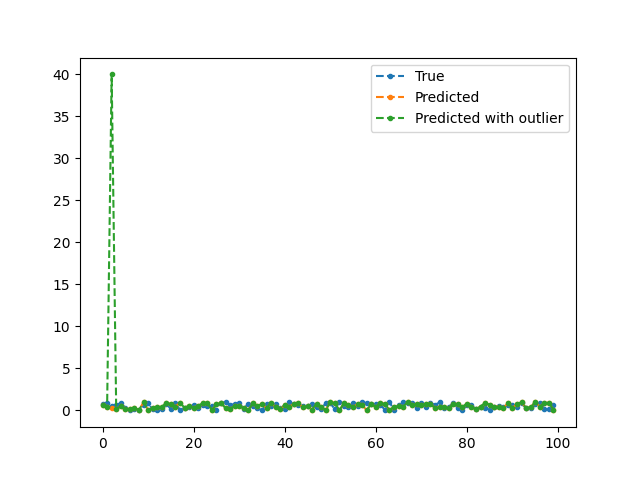
<Axes: >
See the change in mean and median errors. The change in mean error is very high but the change in median error is very low.
Simple Error
Mean: 0.01 --> -0.38
Median: 0.04 --> 0.04
Similarly the change in mean squared error is very large but the change in median squared error is very small.
Squared Error
0.17 --> 15.72
0.1 --> 0.1
Asbolute Error
Mean: 0.34 --> 0.73
Median: 0.32 --> 0.32
Abolute Percentage Error
Mean: 165.63 --> 234.51
Median: 52.26 --> 53.15
So the erros based on mean are more sensitive to outliers than the errors based upon median. Therefore, if the data has outliers and we want to ignore them, we should use median based errors. On the other hand, if we want to focus on the outliers, we should use mean based errors.
Total running time of the script: (0 minutes 0.606 seconds)